
ডেটাবেজ হচ্ছে তথ্য ব্যবস্থাপনার প্রোগ্রাম। ডেটাবেজ ম্যানেজমেন্ট সিস্টেম হচ্ছে হচ্ছে এমন একটি সফটওয়্যার যেখানে ডেটাবেজ তৈরি করা হয়, তথ্য প্রক্রিয়াকরণ করা হয়, ডেটাবেজের প্রচুর পরিমাণ তথ্য একসঙ্গে সংরক্ষণ করা যায়, দরকারি তথ্য বের করা যায়, নতুন তথ্য যোগ করা যায়, প্রয়োজনমতো কোনো তথ্য পরিবর্তন, পরিবর্ধন ও মুছে ফেলা যায় এবং ডেটাবেজ পরিচালনা করা যায়। DBMS ব্যবহারকারী এবং ডেটাবেজের মধ্যে সমন্বয়কারী হিসেবে কাজ করে।
ডেটাবেজ (Database)
ডেটাবেজ শব্দের অর্থ উপাত্ত ঘাঁটি। পারস্পরিক সম্পর্কযুক্ত ডেটা বা তথ্যের সমষ্টিকে ডেটাবেজ (Database সংক্ষেপে DB) বলে। কোন বিষয়ের উপর সম্পর্কযুক্ত উপাত্তসমূহ কম্পিউটারে সুর্গঠিত পদ্ধতিতে বিভিন্ন টেবিলে সংরক্ষণ করা হয়, তখন ঐ টেবিলের সমষ্টিকে বলা হয় ডেটাবেজ। যেমন- কোন কোম্পানির কর্মচারীদের ব্যক্তিগত ফাইলের রেকর্ডসমূহ ডেটাবেজ ফাইলে সংরক্ষণ করা যায়। অর্থাৎ ডেটাবেজ হচ্ছে ডেটাসমৃদ্ধ এক বা একাধিক ফাইলের সমষ্টি। যেমন- গ্রীনিচ ওয়ার্ল্ড, উইকিপিডিয়া, বাংলাপিডিয়া ইত্যাদি। ডেটাবেজ ব্যবহার করলে ডেটাকে আপডেট করা যায়, ডেটার পুনরাবৃত্তি রোধ করা যায়, সাধারণ ফাইল সিস্টেমের তুলনায় ডাটাবেজে মেমোরী খরচ কম হয়।
গঠন অনুযায়ী ডেটাবেজকে দু'ভাগে ভাগ করা যায় যথা-
ক) সাধারণ ডেটাবেজ : শুধুমাত্র একটি টেবিল বা পরস্পর সম্পর্কবিহীন একাধিক টেবিলের সমন্বয়ে গঠিত।
খ) সম্পর্কযুক্ত বা রিলেশনাল ডেটাবেজ : পরস্পর সম্পর্কযুক্ত একাধিক টেবিলের সমন্বয়ে গঠিত ডেটাবেজ।
ডেটাবেজকে মোটাদাগে দু'ভাগে ভাগ করা যায়। যথা-
ক) রিলেশনাল ডেটাবেজ (Relational Database): প্রায় ৫০ বছরের পুরাতন ।
খ) নোএসকিউএল (NoSQL): অপেক্ষাকৃত নতুন। ওয়েবভিত্তিক বিভিন্ন অ্যাপ্লিকেশনে এর ব্যবহার
দিন দিন বাড়ছে ।
ডেটাবেজের লজিক্যাল ডিজাইনকে স্কিমা (Schema) বলা হয় স্কিমা তিন ধরনের হয়, যথা: ফিজিক্যিাল স্কিমা, লজিক্যাল স্কিমা ও ভিউ স্কিমা। ডেটাবেজ ডিজাইনে দুই ধরনের অ্যাপ্রোচ ব্যবহার করা হয় যেমন: টপ-ডাউন অ্যাপ্রোচ ও বটম আপ অ্যাপ্রোচ। টপ-ডাউন অ্যাপ্রোচ এ সাধারণ থেকে শুরু হয়ে নির্দিষ্ট গঠন প্রক্রিয়ায় যায় আর বটম-আপ অ্যাপ্রোচ এ নির্দিষ্ট বিশদ দিয়ে শুরু হয় এবং সাধারণের দিকে চলে যায়।
ডেটাবেজের উপাদান
ডেটা, ফিল্ড, রেকর্ড, ডেটা টেবিল ইত্যাদি হলো ডেটাবেজের উপাদান ।

ডেটা (Data): Data শব্দটি ল্যাটিন শব্দ Datum -এর বহুবচন। Datum অর্থ হচ্ছে তথ্যের উপাদান। প্রাথমিকভাবে সংগৃহীত অসংঘবদ্ধ তথ্যকে বলা হয় ডেটা। সরবরাহকৃত ডেটা থেকে প্রক্রিয়াকরণের পর যে ফলাফল পাওয়া যায় তাকেই বলা হয় তথ্য (Information)। তথ্যের অন্তর্ভুক্ত ক্ষুদ্রতর অংশসমূহ হচ্ছে ডেটা বা উপাত্ত। সকল তথ্যই ডেটা কিন্তু সকল ডেটাই তথ্য নয়। যেমন- কোন ছাত্রের পরীক্ষার ফলাফল হলো তথ্য। কোন ছাত্রের রোল নং, নাম, শাখা ও বিভিন্ন বিষয়ের পরীক্ষার নম্বর হলো ডেটা।

ডেটা টেবিলের বিভিন্ন ফিল্ডে আমরা যা কিছু ইনপুট করি তাই ডেটা। উদাহরণস্বরূপ পূর্বের টেবিলের জাহাঙ্গীর একটি ডেটা যা নাম ফিল্ডের অধীনে আছে। ঢাকা অন্য একটি ডেটা যা ঠিকানা ফিল্ডের অধীনে আছে এবং পিয়ন আরেকটি ডেটা যা পদবি ফিল্ডের অধীনে আছে। ডেটা টেবিলের বিভিন্ন ফিল্ডের অধীনে এন্ট্রিকৃত সব তথ্যই হলো ডেটা।
ফিল্ড (Field): রেকর্ডের ক্ষুদ্রতম অংশ হলো ফিল্ড। রেকর্ডের প্রতিটি উপাদান যেমন- নাম, পদবি, ঠিকানা ইত্যাদিকে এক একটি ফিল্ড হিসেবে ধরা হয়। ফিল্ড হচ্ছে ডেটাবেজের মৌলিক একক বা ভিত্তি। প্রতিটি ফিল্ড সাধারণত কলাম হেডিং হিসেবে থাকে। কলামের একটি সেলের (Cell) ডেটাকে আমরা একটি ফিল্ড হিসেবে ধরি এবং পুরো কলামটিতে একই ধরনের ডেটা থাকে ।
রেকর্ড (Record): অনেকগুলো ফিল্ডের সমন্বয়ে গঠিত হয় একটি রেকর্ড। সাধারণভাবে পুরো একটি সারিকেই আমরা রেকর্ড হিসেবে বিবেচনা করি। যদি কোনো টেবিলে কর্মচারীদের নাম, পদবি ও ঠিকানা লিপিবদ্ধ থাকে, তবে একজন কর্মচারির নাম, পদবি ও ঠিকানা মিলে হবে একটি রেকর্ড। এরকম যতজন কর্মচারির নাম ঠিকানা একটি টেবিলে লিপিবদ্ধ থাকবে সে টেবিলে ততগুলো রেকর্ড আছে বলে ধরা হবে। কখনো কখনো রেকর্ডকে টাপল (Tuple) বা সারি (Row) বলা যায়। পরস্পর সম্পর্কযুক্ত দুই বা ততোধিক রেকর্ড নিয়ে গঠিত হয় ফাইল বা নথি ।
ডেটা টেবিল (Data Table): এক বা একাধিক রেকর্ড নিয়ে ডেটা টেবিল গঠিত। টেবিল হলো ডেটাবেজের প্রাণ। এক বা একাধিক ডেটা টেবিল নিয়ে ডেটাবেজ গঠিত। সমজাতীয় সকল ডেটাকে এক একটি টেবিলে সংরক্ষণ করে রাখা হয়। ধরা যাক, একটি অফিসের তিনটি শাখা আছে, যথা- প্রশাসন শাখা, হিসাব শাখা ও বিক্রয় শাখা। প্রশাসনিক কর্মকাণ্ডের জন্য একটি টেবিল নির্দিষ্ট করা আছে যেখানে ঐ শাখার সকল উপাত্ত সংরক্ষিত আছে। হিসাব শাখার জন্য আবার আলাদা একটি টেবিলে অফিসের আয়-ব্যয় বা কর্মচারীদের বেতন-ভাতার হিসাব সংরক্ষিত আছে এবং বিক্রয় শাখার জন্য আর একটি টেবিলে দৈনন্দিন বিক্রয় সংক্রান্ত নথিপত্র লিপিবদ্ধ আছে। তিনটি টেবিলই থাকবে একটি মূল ফাইল বা ডেটাবেজের অধীনে।
এনটিটি
এনটিটি (Entity) : কোনো ডেটাবেজের বৈশিষ্ট্য প্রকাশের জন্য যে রেকর্ড ব্যবহার করা হয় তাকে এনটিটি বলে। এনটিটি হচ্ছে সত্তা যা দিয়ে অবজেক্টকে চিহ্নিত করা যায়। কোন ডেটা টেবিলকে চিহ্নিত করার জন্য টেবিলের যে নাম দেওয়া হয় তাই হচ্ছে ডেটার এনটিটি। যেমন- একজন কর্মচারীর নাম, পদবি, বয়স, ঠিকানা ইত্যাদির সমন্বয়ে এনটিটি গঠিত হয়। এনটিটির বাস্তব উপস্থিতি থাকতে পারে আবার শুধুমাত্র ধারণার উপর ভিত্তি করে হতে পারে। নিচের চিত্রের মাধ্যমে এনটিটি দেখানো হলো-
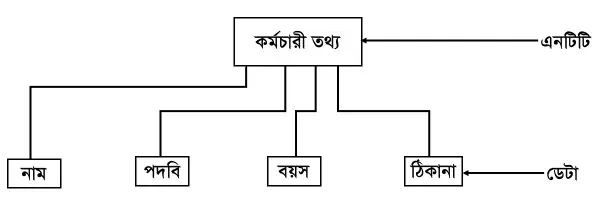
এনটিটি সেট (Entity Set): একই জাতীয় এনটিটিকে এনটিটি সেট (Entity Set) বলা হয়। একটি ডেটাবেজকে এনটিটি সেট বলা যেতে পারে।
এট্রিবিউট (Attribute)/ ফিল্ড (Field)/ কলাম (Column): একটি এনটিটি এর বৈশিষ্ট্য প্রকাশের যে সমস্ত ফিল্ড বা আইটেম বা উপাদান ব্যবহার করা হয় তাকে বলা হয় এট্রিবিউট। অর্থাৎ এনটিটির অন্তর্ভুক্ত প্রত্যেকটি ফিল্ডকে এট্রিবিউট বলে। নিচের এনটিটিতে তিনটি ফিল্ড রয়েছে। এগুলো হলো নাম, পদবি এবং ঠিকানা। এর প্রত্যেকটি এক একটি এট্রিবিউট। কোন একজন কর্মচারীর উল্লিখিত তিনটি ফিল্ডের যে তথ্য পাওয়া যাবে, সেই তিনটি তথ্যের সমষ্টিকে বলা হয় এনটিটি সেট বা রেকর্ড। যেমন- সোহেল, অফিসার, বগুড়া এ তিনটি ফিল্ড একটি এনটিটি সেট।
| নাম | পদবি | ঠিকানা |
|---|---|---|
| জাহাঙ্গীর | ম্যানেজার | ঢাকা |
| সোহেল | অফিসার | |
| কাজল | পিয়ন | বগুড়া |
ভ্যালু (Value): প্রত্যেকটি এট্রিবিউট এর যে মান থাকে তাকে বলা হয় ভ্যালু। যেমন- উপরের এনটিটিতে নাম এট্রিবিউট এর ভ্যালু হচ্ছে সোহেল, পদবি এট্রিবিউট এর ভ্যালু হচ্ছে অফিসার। কোন এট্রিবিউট এর মান যদি না থাকে বা ফাঁকা থাকে, তখন তার ভ্যালু হবে Null। যেমন- উপরের এনটিটিতে সোহেলের ঠিকানার ভ্যালু Null। কোন কলাম বা এট্রিবিউট এর মান ইউনিক বা অদ্বিতীয় হলে তাকে ডোমেইন (Domain) বলে।
এনটিটি রিলেশনশীপ মডেল
ডেটাবেজের অন্তর্গত ডেটা ফাইলসমূহের লজিক্যাল গঠনকে বা সম্পর্ককে যে ব্লক ডায়াগ্রামের সাহায্যে বিকাশ করা হয় তাকে এনটিটি রিলেশনশীপ মডেল বলে। এটা ডেটাবেজ ডিজাইনে বহুল ব্যবহৃত একটি মডেল। উদাহরণ হিসেবে নিচে একটি এনটিটি রিলেশনশীপ মডেল দেখানো হলো-

এখানে দুইটি এনটিটি রয়েছে স্টুডেন্ট (student) ও ক্লাশ (class)। স্টুডেন্ট টেবিলের চারটি ফিল্ড।। আইডি, প্রথম নাম, শেষ নাম, মেজর ইত্যাদি এবং ক্লাশ টেবিলের তিনটি ফিল্ড- ক্লাশ নম্বর, সিডিউল , রুম ইত্যাদি। দুই টেবিলের মধ্যে একটি রিলেশনশীপ এনরোল (Enroll) তৈরি করে দেখানো হয়েছে। এনটিটি রিলেশনশীপ মডেলের প্রত্যেকটি জ্যামিতিক চিত্রের নিজস্ব অর্থ আছে। যেমন:

কী (Key) : সাধারণত কোনো একটি ফিল্ডের উপর ভিত্তি করে ফাইলের রেকর্ড সনাক্তকরণ, অনুসন্ধান, সম্পর্ক স্থাপন ইত্যাদি কাজগুলো করা হয়। এই ফিল্ডকে কী ফিল্ড বলে। যেমন- ক্লাশে ছাত্রদের রোল নম্বরের ভিত্তিতে শনাক্তকরণ, ফলাফল ঘোষণা ও স্কলারশীপ বিতরণ করা হয়, তাই রোল নম্বরকে কী ফিল্ড বলা যায়। নিম্নে কী ফিল্ডগুলো আলোচনা করা হলো-
প্রাইমারি কী (Primary Key): প্রাইমারি কী হচ্ছে একটি টেবিলের নির্দিষ্ট ফিল্ড, যেটি দিয়ে প্রতিটি রেকর্ডকে আলাদাভাবে চিহ্নিত করা যায়। একটি টেবিলে একটি মাত্র প্রাইমারী কী ফিল্ড থাকবে। এ ফিল্ডের ডেটাগুলো ইউনিক বা অদ্বিতীয় হবে। যেমন- একটি শ্রেণিতে শিক্ষার্থীদের রোল নম্বর একটিই থাকে। তাই রোল নম্বরটিই হলো প্রাইমারি কী। নিম্নের ছাত্রদের ভর্তি ফাইলে প্রাইমার কী ফিল্ড দেখানো হলো-
| রোল | নাম | বয়স |
|---|---|---|
| ১৭২ | তাহমিদ হোসেন | ১০ বছর |
| ১৮৯ | সাদিকা তাইয়িবা | ১০ বছর |
| ২০২ | মাকসুদা আখতার | ৯ বছর |
রোল নম্বর ছাড়া অন্য কোনো ফিল্ডকে প্রাইমারি কী বলা যাবে না কারণ নাম ফিল্ডে একই নাম একাধিকবার থাকতে পারে কিংবা বয়স বা অন্যান্য ফিল্ডের একই ডেটা বার বার থাকতে পারে। প্রাইমারি কী এর সাহায্যে একাধিক ফাইলের মধ্যে সম্পর্ক স্থাপন করে রিলেশনাল ডেটাবেজ তৈরি করা হয়।
কম্পোজিট প্রাইমারি কী (Composite Primary Key): যখন কোন ডেটাবেজ ফাইলে কোনো সুনির্দিষ্ট প্রাইমারি কী থাকে না, তখন একটি ফিল্ডকে প্রাইমারি কী ফিল্ড হিসাবে ব্যবহার করা যায় না। সে সব ক্ষেত্রে একাধিক ফিল্ডকে একত্রে প্রাইমারি কী ফিল্ড হিসেবে ব্যবহার করা হয়। এ ধরনের প্রাইমারি কী ফিল্ডকে বলা হয় কম্পোজিট প্রাইমারি কী ফিল্ড। এ কম্পোজিট প্রাইমারী কী-গুলোর একটিকে প্রাথমিক কী বিবেচনা করে বাকিগুলোকে বলা হবে অল্টারনেট কী।
| ক্লাস | রোল নং | ছাত্রের নাম |
|---|---|---|
| প্রথম | ১০ | তাহমিদ |
| দ্বিতীয় | ১১ | সবুজ |
| তৃতীয় | ১১ | সালাম |
| চতুর্থ | ১৫ | জাহিন |
উপরের টেবিলে রোল নং ফিল্ডকে প্রাইমারী কী হিসেবে বিবেচনা করে আমরা কোন রেকর্ডকে আলাদা করতে পারছি না কারণ বিভিন্ন ক্লাসের ছাত্রের একই রোল নং আছে। এক্ষেত্রে রোল নং ফিল্ডের সাথে ক্লাস ফিল্ডকে যোগ করে প্রাইমারী কী হিসেবে যে কোন রেকর্ডকে আলাদা করতে পারি।
ফরেন কী (Foreign Key): কোন একটি টেবিলের প্রাইমারি কী যদি অন্য টেবিলে সাধারণ কী হিসেবে ব্যবহৃত হয় তখন ঐ কী-কে ফরেন কী বলে। ফরেন কীর সাহায্যে একটি টেবিলের সাথে অন্য টেবিলের সম্পর্ক স্থাপন করা হয়। প্রথম টেবিলকে পেরেন্ট টেবিল বা রেফারেন্স টেবিল আর দ্বিতীয় টেবিলকে চাইল্ড বা ডিটেইলস টেবিল বলে।
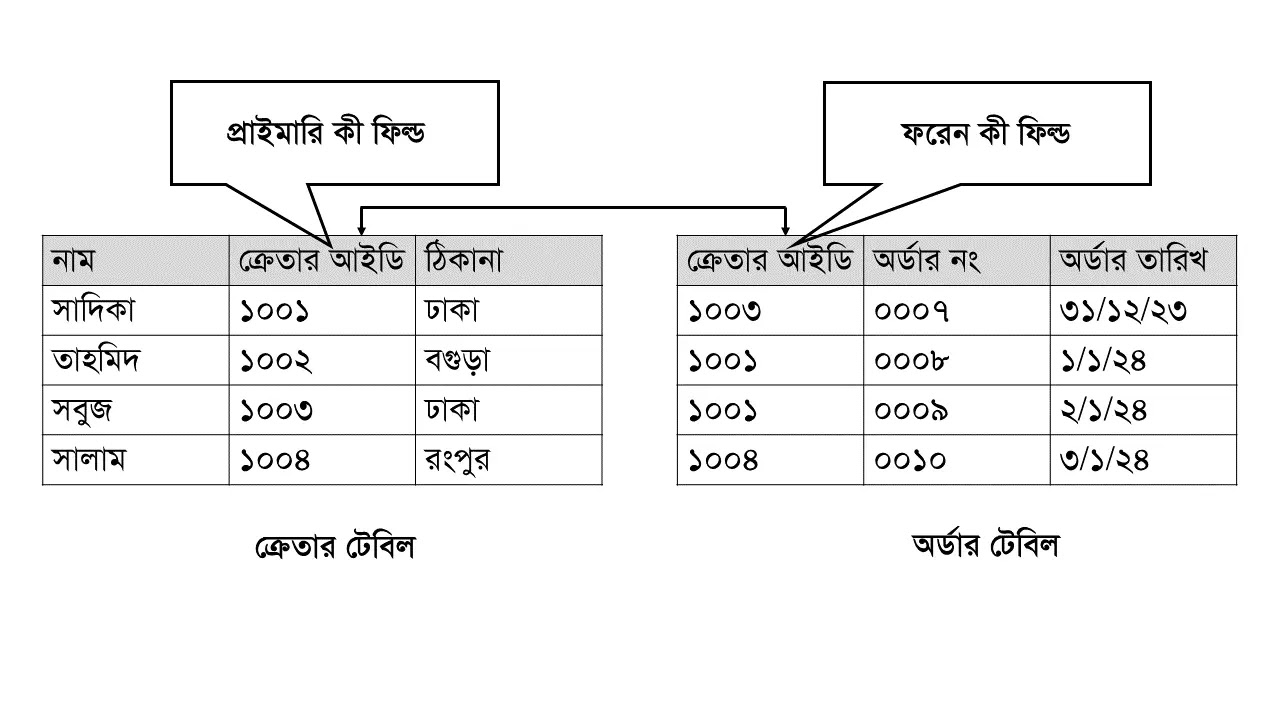
অর্ডার টেবিলের প্রাইমারি কী হলো অর্ডার নং এবং ফরেন কী হলো ক্রেতার আইডি।
সুপার কী (Super Key) : প্রাইমারী কী এর সুপারসেট। সুপার কী-টিতে প্রাথামিক কী সহ বৈশিষ্ট্যগুলির একটি সেট রয়েছে যা টেবিলের কোন রেকর্ডকে ইউনিক হিসেবে সনাক্ত করতে পারে।
| রেজি: নং | রোল নং | নাম |
|---|---|---|
| ২০২১০০২০ | কগ ০৫২০ | হাশিম |
| ২০২১০০২১ | কগ ০৫২১ | রিদওয়ান |
| ২০২১০০২২ | কগ ০৫২২ | এমিলি |
উপরের টেবিলের রেজি: নং, রোল নং এবং নাম হলো সুপার কী।
অল্টারনেট কী (Alternate Key) হলো এক বা একাধিক কলামের সমষ্টি যা টেবিলের প্রত্যেকটি রেকর্ডকে আলাদা করতে পারে। একটি টেবিলে অনেকগুলি ফিল্ড প্রাইমারী কী হিসেবে নির্ধারণের সুযোগ থাকলেও একটি ফিল্ডকে প্রাইমারী কী হিসেবে নির্দিষ্ট করা হয়। প্রাইমারী কী ফিল্ড ব্যতীত অন্য ফিল্ডগুলোকে বলা হয় অল্টারনেট কী।
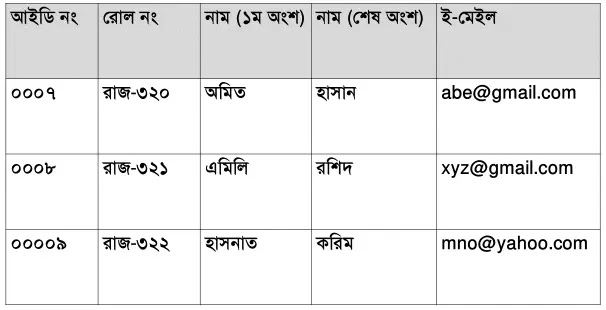
উপরের টেবিলে আইডি নং, রোল নং ও ই-মেইল প্রাইমারী কী হতে পারে। যেহেতু আইডি নং কে প্রাইমারী কী হিসেবে নির্ধারণ করা হয়েছে সেহেতু রোল নং ও ই-মেইল অল্টারনেট কী।
ক্যান্ডিডেট কী (Candidate key) একটি সুপার কী, যার কোন পুনরাবৃত্তির বৈশিষ্ট্য নেই। ক্যান্ডিডেট কী এমন একটি বৈশিষ্ট্যের সমষ্টি যা কোনো রেকর্ডকে আলাদাভাবে সনাক্ত করতে পারে। সর্বনিম্ন সুপার কী-গুলোকে ক্যান্ডিডেট কী বলা হয়।
উপরের টেবিলে আইডি নং, রোল নং ও ই-মেইল হলো ক্যান্ডিডেট কী। কারণ এ সকল ফিল্ডের মাধ্যমে টেবিলের রেকর্ডকে আলাদা করা যায়।
ডেটাবেজ ম্যানেজমেন্ট সিস্টেম
ডেটা হচ্ছে তথ্য আর ডেটাবেজ মানে হচ্ছে তথ্যভান্ডার। কম্পিউটার আবিষ্কারের আগে পর্যন্ত ফাইলের স্তুপে জমা থাকতো তথ্য, এখন তথ্য সংরক্ষণ করা হয় ডেটাবেজে। ডেটাবেজ ম্যানেজমেন্ট সিস্টেমের কার্যক্রমকে দুটি ভাগে ভাগ করা যায়। যথা:
- ফ্রন্ট এন্ড: গ্রাফিক্যাল ইউজার ইন্টারফেস তৈরির জন্য যে সকল টুলস ব্যবহার করা হয়। যেমন: ফর্ম, রির্পোট, ইত্যাদি।
- ব্যাক এন্ড: যেখানে ডেটা জমা থাকে তাকে ব্যাক এন্ড বলে। যেমন: টেবিল, ভিউ ইত্যাদি।
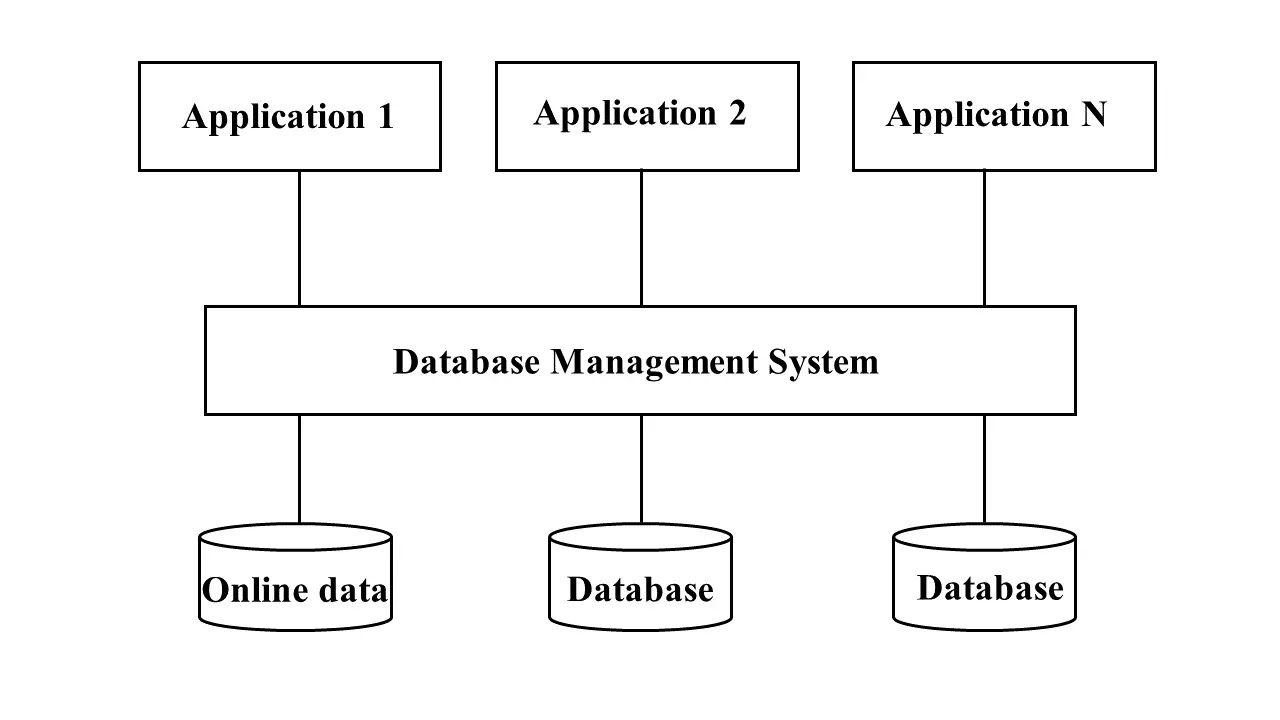
বর্তমানে বিভিন্ন ধরনের ডেটাবেজ ম্যানেজমেন্ট সিস্টেম কম্পিউটারে ব্যবহার করা হয়। যেমন-
- Open Source DBMS এর সোর্স কোড সকলের জন্য উন্মুক্ত। এই সকল সফটওয়্যার বিনা মূল্যে সংগ্রহ করা যায় এবং যে কেউ এই সকল কোড তার খুশীমত পরিবর্তন, পরিবর্ধন, পরিমার্জন ইত্যাদি করে নিজে ব্যবহার ও অন্যকে ব্যবহারের জন্য বিতরণ করতে পারে। যেমন- MySQL, IBM DB2, PostgreSQL, Maria DB, Cassandra, SQLite, Cubrid, Altibase ইত্যাদি।
- ক্লোজড সোর্স বা প্রোপাইটরি DBMS এর সোর্স কোড সকলের জন্য উন্মুক্ত থাকে না, যে কেউ চাইলেই তা পরিবর্তন, পরিবর্ধন বা পরিমার্জন করতে পারে না। এ সকল সফটওয়্যারের স্বত্ত্ব বা মালিকানা আইনগতভাবে নির্দিষ্ট করা থাকে। যেমন- ORACLE ওরাকল (Oracle), মাইক্রোসফট এ্যাকসেস (Microsoft Access), মাইক্রোসফ্ট এসকিউএল সার্ভার (Microsoft SQL Server), ডিবেজ (dbase), ইনফরমিক্স (Informix), কোরেল প্যারাডক্স (Corel Paradox), লোটাস এপ্রোচ (Lotus Approach), ভিজুয়্যাল ফক্সপ্রো (Visual Foxpro), ফাইলমেকার প্রো (FileMaker Pro) ইত্যাদি।
প্রয়োজনীয় তথ্য সংরক্ষণ ও তা ব্যবহারের জন্য বিশেষ সফটওয়্যার দ্বারা তৈরিকৃত বহুমুখী সুবিধা সম্পন্ন ইন্টারনেটভিত্তিক ডেটাবেজ ম্যানেজমেন্ট সিস্টেমকে কর্পোরেট ডেটাবেজ বলে। বড় বড় এন্টারপ্রাইজ বা কর্পোরেট প্রতিষ্ঠান যেমন ব্যাংক বিমা, মাল্টিন্যাশনাল কোম্পানি, সরকারি প্রতিষ্ঠান, এনজিও এবং নেটওয়াকিং দ্বারা পরিচালিত সকল প্রতিষ্ঠান ই আরপি (ERP - Enterprise Resource Planning) নামের ডেটাবেজ সফটওয়্যার ব্যবহার করে থাকে ।
রিলেশনাল ডেটাবেজ ম্যানেজমেন্ট সিস্টেম
Relational database management system - RDMS
RDMS হচ্ছে একটি সফটওয়্যার সিস্টেম যা পরস্পর সম্পর্কযুক্ত তথ্য এবং সেই তথ্যগুলো পর্যালোচনা করার জন্য প্রয়োজনীয় প্রোগ্রামের সমষ্টি। একটি ডেটাবেজে একাধিক টেবিল থাকতে পারে। কোন একটি নির্দিষ্ট ফিল্ডের উপর ভিত্তি করে দুই বা ততোধিক টেবিলের মধ্যে সম্পর্ক স্থাপন করাকে রিলেশনশীপ বলা হয়। রিলেশন তৈরি করা টেবিল থেকে প্রয়োজনীয় ডেটা নিয়ে আলাদা ডেটা টেবিল তৈরি করা যায়। রিলেশন করা ডেটা টেবিলের সমন্বয়ে গঠিত ডেটাবেজকে রিলেশনাল ডেটাবেজ বলা হয়। আধুনিক ডেটাবেজ সফটওয়্যার বলতে সাধারণত রিলেশনাল ডেটাবেজ ম্যানেজমেন্ট সিস্টেমকেই বুঝায়। RDMS ডেটাবেজ এবং ডেটাবেজ ব্যবহারকারীর মধ্যে সমন্বয়কারী সফটওয়্যার হিসেবে কাজ করে। RDMS এর সাহায্যে ফাইল তৈরি, রক্ষণাবেক্ষণ, নিরাপত্তা ইত্যাদি নিয়ন্ত্রণ করা যায়। রিলেশনাল ম্যানেজমেন্ট প্রোগ্রামে একাধিক ডেটা টেবিল, কুয়েরি, ফর্ম, রিপোর্ট থাকতে পারে। রিলেশনাল ডেটাবেজ মডেলে ডেটার তিনটি দিক রয়েছে। যথা-
- ডেটা স্ট্রাকচার (Data Structure): একটি নির্দিষ্ট ডেটা সংগঠনের যৌক্তিক অথবা গাণিতিক মডেলকে ডেটা স্ট্রাকচার বলে।
- ডেটা ইন্টিগ্রিটি (Data Integrity) : ডেটা ইন্টিগ্রিটি বলতে পারস্পরিক সম্পর্কযুক্ত ডেটার পরিপূর্ণতাকে বুঝায় ।
- ডেটা ম্যানিপুলেশন (Data Manipulation): রেকর্ড সংযোজন, সংরক্ষণ, পরিবর্তন, আহরণ ইত্যাদিকে একত্রে ডেটা ম্যানিপুলেশন বলে।
ইংরেজ কম্পিউটার বিজ্ঞানী এডগার ফ্রাঙ্ক কড (Edgar Frank Codd) ১৯৮৫ সালে RDMS বাস্তবায়ন করার জন্য Codd's Twelve rules নামে পরিচিত ১৩টি নিয়ম প্রস্তাবনা করেন। এর উপর ভিত্তি করে RDMS টার্মটি স্বীকৃতি পায়।
রিলেশনাল ডেটাবেজ ম্যানেজমেন্ট সিস্টেম সার্ভারে ডেটাবেজ ইঞ্জিন ব্যবহার করার জন্য বাজারে অনেক ধরনের সফট্ওয়্যার রয়েছে। যথা- ওরাকল (Oracle), মাইএসকিউএল (MySQL), মাইক্রোসফ্ট এ্যাকসেস (Microsoft Access), মাইক্রোসফ্ট এসকিউএল সার্ভার (Microsoft SQL Server), ইনফরমিক্স (Informix), কোরেল প্যারাডক্স (Corel Paradox), লোটাস এপ্রোচ (Lotus Approach), ভিজুয়্যাল ফক্সপ্রো (Visual Foxpro), ফাইল মেকার প্রো (FileMaker Pro), ফোর্থ ডাইমেনশন (4D), পোস্টগ্রেএসকিউএল (PostgreSQL), এসকিউলাইট (SQLite) ইত্যাদি।
- Visual Foxpro একটি চিত্র নির্ভর প্রোগ্রাম।
- ফাইলমেকার প্রো প্রোগ্রামটির নির্মাতা যুক্তরাষ্ট্রের ক্লারিস নামক প্রতিষ্ঠান।
কুয়েরি (Query)
ডেটাবেজে এক বা একাধিক টেবিলে সংরক্ষিত বিপুল পরিমাণ ডেটা থেকে প্রয়োজনীয় যেকোনো সংখ্যক ডেটাকে দ্রুত বা খুব সহজে খুঁজে বের করা, প্রদর্শন করা বা ছাপানোর কার্যকরি পদ্ধতিকে কুয়েরি বলা হয়। কুয়েরিতে Expression, Operator, Filter ইত্যাদি ব্যবহার করা হয়। কোন ডেটা কুয়েরি করার জন্য যুক্তিমূলক এক্সপ্রেশন (Logical Expression) দিয়ে শর্ত নির্ধারণ করে দিতে হয়। যে সকল রেকর্ড শর্ত পূরণ করে সে রেকর্ডগুলোই কুয়েরির ফলাফল হিসেবে পাওয়া যাবে। যেমন- ধরা যাক, কোন ডেটা টেবিলে City নামক একটি ফিল্ডে বিভিন্ন শহরের নাম আছে। এক্ষেত্রে যে সকল রেকর্ডের City ফিল্ডের মান "Bogura" আছে, সে রেকর্ডগুলো কুয়েরি করার জন্য City = "Bogura" এ রকম এক্সপ্রেশন তৈরি করা যায়। কুয়েরিতে এক্সপ্রেশন তৈরি করার জন্য বিভিন্ন অপারেটর ব্যবহার করতে হয়। কাজের উপর ভিত্তি করে কুয়েরিকে কয়েক ভাগে ভাগ করা হয়। যেমন:
- Select Query : একাধিক ডেটা টেবিল থেকে ফিল্ড বেছে নিয়ে কুয়েরি করার জন্য ব্যবহার করা হয়।
- Parameter Query: ফিল্ড অনুসারে ডায়ালগ বক্স থেকে বিভিন্ন প্যারামিটার বা তথ্য নির্বাচন করে কুয়েরি করার জন্য ব্যবহার করা হয়।
- Crosstab Query: কুয়েরি করা ফলাফলকে সামারি আকারে ডেটা শিট ফর্মে উপস্থাপন করার জন্য ব্যবহার করা হয়।
- Action Query: কোনো কুয়েরির ফলাফল দিয়ে নতুন টেবিল তৈরি করার জন্য ব্যবহার করা হয়।
কুয়েরি ল্যাঙ্গুয়েজ (Query Language)
যে ল্যাঙ্গুয়েজের সাহায্যে ডেটাবেজ থেকে শর্তসাপেক্ষে নির্দিষ্ট ডেটাকে তল্লাশি বা খুঁজে বের করে Insert. Delete, Modify ইত্যাদি করা যায়, সে ল্যাঙ্গুয়েজকে কুয়েরি ল্যাঙ্গুয়েজ বলা হয়। ৩টি কুয়েরি ল্যাংগুয়েজ সর্বাধিক গ্রহণযোগ্যতা পেয়েছে। যথা-QUEL-Query Language, QBE- Query By Example, SQI. Structured Query Language .
SQL (Structured Query Language): রিলেশনাল ডেটাবেজে SQL নামক প্রোগ্রামিং ভাষার সাহায্যে ডেটাবেজে তথ্য লেখা, পড়া,
পরিবর্তন করা ও অন্যান্য কাজ করা হয়। ১৯৭৪ সালে আইবিএম স্যান জুস গবেষণা কেন্দ্রে SQL উদ্ভাবন করে।
SQL-
- একটি ডিক্লারেটিভ (Declarative) বা নন প্রসিডিউরাল (non-procedural) প্রোগ্রামিং ভাষা কারণ এসকিউএল কুয়েরি লেখার সময় কী করতে হবে সেটি বলে দিতে হয়। আর সেই কাজটি কীভাবে করা হবে সেটা নির্ভর করে ডেটাবেজ সিস্টেমের উপর।
- একই সময়ে এক একটি রেকর্ডকে প্রসেস না করে বরং এক সেট রেকর্ড প্রসেস করে। অধিকাংশ SQL স্টেটমেন্টই ফলাফল হিসেবে এক সেট রেকর্ড প্রদান করে।
- SQL ডেটাবেজ ব্যবহারকারীদের মাঝে খুবই জনপ্রিয়। একারণে বিভিন্ন ডেটাবেজ পণ্য (যেমন- MySQL, Oracle, Sybase, SQL Server, Postgres প্রভৃতি) এ SQL সন্নিবেশিত করা হয়।
SQL কে কয়েক ভাগে ভাগ করা যায়। যথা:
ক) ডেটা ডেফিনেশন ল্যাঙ্গুয়েজ (Data Definition Language - DDL): ডেটাবেজের টেবিল তৈরি করা, টেবিল মুছে ফেলা, ইনডেক্স তৈরি করা ইত্যাদি কাজ করার জন্য
ডেটা ডেফিনেশন ল্যাঙ্গুয়েজ ব্যবহার করা হয়। যেমন-একটি টেবিল তৈরি করতে গেলে টেবিলের নাম,
টেবিলের বিভিন্ন কলামের নাম ও সেখানে কী ধরনের ডেটা থাকবে, ইনডেক্স ইত্যাদি বলে দিতে হয়। ডেটা ডেফিনেশন ল্যাঙ্গুয়েজ এর কমান্ডগুলো হল-
Create statement : নতুন ডেটাবেজ তেরি করার জন্য ।
Alter statement : টেবিলের স্ট্রাকচার পরিবর্তন করার জন্য ।
Drop statement : ডেটাবেজ বা টেবিল ডিলিট করার জন্য।
Rename statement : টেবিলের নাম পরিবর্তন করার জন্য।
খ) ডেটা ম্যানিপুলেশন ল্যাঙ্গুয়েজ (Data Manipulation Language DML): ডেটা ম্যানিপুলেশন ল্যাঙ্গুয়েজের সাহায্যে একটি টেবিলের ডেটার উপর বিভিন্ন ধরনের কুয়েরি চালানো হয়,
যেমন- ডেটা পড়া, ডেটা পরিবর্তন করা, ডেটা মুছে ফেলা, ডেটা সংযোজন করা ইত্যাদি। ডেটা ম্যানিপুলেশন ল্যাঙ্গুয়েজ এর কমান্ডগুলো হল :
Select statement : শর্ত সাপেক্ষে ডেটা নির্বাচন করার জন্য। তুলনা করার জন্য শর্তে Compare, নির্দিষ্ট সীমার মধ্যে নেওয়ার জন্য Between AND, সকল রেকর্ড নেওয়ার জন্য IN ব্যবহার করতে হয়।
Insert statement : রেকর্ড সংযোজন করার জন্য ।
Update statement : আপডেট করার জন্য ।
Delete statement : সারি মুছে ফেলার জন্য।
গ) ডেটা কন্ট্রোল ল্যাঙ্গুয়েজ (Data Control Language - DCL): DCL সীমিত ডেটার মধ্যে একসেস করার বিশেষাধিকার প্রদান করে। ডেটা কন্ট্রোল ল্যাঙ্গুয়েজ এর কমান্ডগুলো হল-
GRANT : ব্যবহারকারীকে ডেটাবেজের ডেটাতে একসেস করার বিশেষাধিকার প্রদান করে।
REVOKE : স্টেটমেন্ট কর্তৃক দেওয়া অ্যাকসেস সুবিধা ফিরিয়ে নেয়।
COMMENT : ডেটা টেবিলে কমেন্ট লেখার জন্য
ঘ) ট্রান্সজেকশন কন্ট্রোল স্টেটমেন্ট (Transaction Control Statement - TCS): ডেটাবেজের ভিতর ডেটার লেনদেনকে পরিচালনা করতে TCS কমান্ডসমূহ ব্যবহৃত হয়।
ট্রান্সজেকশন কন্ট্রোল স্টেটমেন্ট এর কমান্ডগুলো হল-
COMMIT : ডেটার পরিবর্তনকে ডেটাবেজে স্থায়ীভাবে সংরক্ষণ করে।
ROLL NOBACK : COMMIT করার কারণে পরিবর্তনকে পূর্বাবস্থায় ফিরয়ে আনে।
সমষ্টিগত ফাংশন (Aggregate function): ডেটাবেজ ম্যানেজমেন্টে, সমষ্টিগত বা একত্রীকরণ ফাংশন হল এমন একটি ফাংশন যেখানে একাধিক সারির মান একত্রিত হয়ে একটি একক সারাংশ মান গঠন করে। যেমন- Average, Count, Maximum, Median, Minimum, Mode, Range, Sum ইত্যাদি।
ডেটা টাইপ
| ডেটা টাইপ | সাইজ বা আকার | বর্ণনা |
|---|---|---|
| Text/ Character | ২৫৫ ক্যারেক্টার পর্যন্ত | সাধারণত বর্ণভিত্তিক ডেটার ক্ষেত্রে এ ডেটা টাইপ ব্যবহার করা হয়। যেমন: Name, Father's name, Designation, Address ইত্যাদি। |
| Number/ Numeric | ১,২,৪ বা ৮ বাইট | সংখ্যাভিত্তিক বা সংখ্যা জাতীয় ডেটার ক্ষেত্রে পূর্ণসংখ্যা কিংবা দশমিক সংখ্যা লেখা যায়। এ ফিল্ডে কোন বর্ণ লেখা যায় না। যেমন: Marks, GPA, Mobile No ইত্যাদি। |
| Auto Number | ৪ বাইট | সাধারণত ধারাবাহিক বা সিরিজ জাতীয় ডেটার ক্ষেত্রে ব্যবহার করা হয়। যেমন: Sl.No,ID No, Roll No ইত্যাদি। |
| Currency | ৮ বাইট | মুদ্রা বা অর্থ জাতীয় ডেটার ক্ষেত্রে এ ডেটা টাইপ ব্যবহার করা হয়। যেমন: Tution Fee, Salary, Exam Fee, Service Charge ইত্যাদি। |
| Date/ Time | ৮ বাইট | তারিখ ও সময় জাতীয় ডেটার ক্ষেত্রে এ ডেটা টাইপ ব্যবহার করা হয়। যেমন: Date of Birth, Joining date, Admission date ইত্যাদি। ১০০ সাল থেকে ৯৯৯৯ সাল পর্যন্ত যে কোন বছরের তারিখ বা সময় এই ফিল্ডে লিপিবদ্ধ করা যায়। |
| Logical | ১ বিট | যে সমস্ত ডেটা কেবলমাত্র হ্যাঁ বা না দ্বারা সম্পূর্ণরুপে প্রকাশ করা যায়, ঐ জাতীয় ডেটার ক্ষেত্রে এ ডেটা টাইপ ব্যবহার করা হয়। যেমন: Present, Absent, Married-unmarried ইত্যাদি। |
| Memo | ১ গিগা বাইট পর্যন্ত | ইহা একটি Conditional ও বড় ডেটা টাইপ। এ জাতীয় ফিল্ডে বর্ণ, সংখ্যা, চিহ্ন, তারিখ ইত্যাদি ৬৫,৫৩৬ সংখ্যা বর্ণ লেখা যায়। সাধারণত মন্তব্য (Remarks), History, Reference ইত্যাদি ফিল্ডে এ ডেটা টাইপ ব্যবহার করা হয়। |
| OLE Object | প্রায় ২ গিগাবাইট | ইহার পূর্ণরূপ হচ্ছে Object Linking and Embedding যে সমস্ত তথ্য ডেটাবেজে নয় অন্য সফটওয়্যারে করা আছে এমন সব ডেটা যেমন-ইমেজ, পিকচার ইত্যাদি Link এর মাধ্যমে স্বয়ংক্রিয়ভাবে ডেটাবেজে নেওয়ার ক্ষেত্রে এ ডেটা টাইপ ব্যবহার করা হয়। |
| Hyperlink | ৮১৯২ ক্যারেক্টার | সাধারণত ডেটাবেজ প্রোগ্রামের সাথে ওয়েব পেজের কোন ফাইল কিংবা অন্য কোন ব্যবহারিক প্রোগ্রামের ফাইল লিংক বা রিলেশন সৃষ্টি করার জন্য এ ডেটা টাইপ ব্যবহার করা হয়। |
| Look up Wizard | - | এ জাতীয় ফিল্ডে ডেটা সুনির্দিষ্ট করা থাকে, কোন এন্ট্রি করার প্রয়োজন হয় না। যেমন: Group, Borad, Country ইত্যাদি। |
| Attachment | প্রায় ২ গিগাবাইট | ছবি, ওয়ার্ড ডকুমেন্ট, স্প্রেডশিট ইত্যাদি অন্যান্য সফটওয়্যারে করা বড় আকৃতির ফাইল রেকর্ডে সংযুক্ত করা যায়। |
সার্চিং, সর্টিং ও ইনডেক্সিং
সার্চিং প্রক্রিয়ায় ডাটাবেজ থেকে প্রয়োজনীয় রেকর্ড বা তথ্য খুঁজে বের করা হয়।
সর্টিং প্রক্রিয়ায় ডেটা টেবিলের ডেটাগুলোকে নির্দিষ্টক্রমে অর্থাৎ ছোট থেকে বড় বা বড় থেকে ছোট আকারে সাজানো যায়। রেকর্ডসমূহকে দু'ভাবে সর্ট করা যায়। যেমন:
১। Ascending (আরোহী বা উচ্চ ক্রমানুসারে) → ছোট থেকে বড় আকারে। যেমন- A to Z.
২। Descending (অবরোহী বা নিম্ন ক্রমানুসারে) → বড় থেকে ছোট আকারে। যেমন- Z to A.
সিলেক্ট কুয়েরির শেষে- -
• 'Order by' লিখে কলামের নাম লিখলে সেই কলামের নাম অনুসারে ছোট থেকে বড় ক্রমে আসবে।
• কলামের পর 'DESC' লিখলে বড় থেকে ছোট ক্রমে ডেটা আসবে।
সটিং করতে অবশ্যই সার্চিং করতে হয়, কিন্তু সার্চিং করতে সর্টিং প্রয়োজন হয় না।
ইনডেক্সিং হচ্ছে একটি বিশেষ পদ্ধতি, যার মাধ্যমে ব্যবহারকারী যাতে সহজে ও দ্রুত ডেটা খুঁজে বের করতে পারে সেজন্য ডেটাকে একটি বিশেষ অর্ডারে সাজিয়ে রাখা হয়। ডেটাবেজের টেবিলের রেকর্ডসমূহকে এরূপ লজিক্যাল অর্ডারে সাজিয়ে রাখাকেই ইনডেক্সিং বলে। লজিক্যাল, হাইপারলিংক ও OLE Object ফিল্ডের উপর ইনডেক্স করা হয় না।
ইনডেক্সিং ও সর্টিং এর তুলনা :
- ডেটা ফাইলকে সর্ট করা হলে ইনডেক্সিং পদ্ধতিতে মূল টেবিলে ফাইলের রেকর্ডের সিরিয়াল ঠিক থাকে কিন্তু সর্টিং পদ্ধতিতে মূল টেবিল ফাইলের রেকর্ডের সিরিয়াল ঠিক থাকে না।
- ডেটাবেজ ফাইলে নতুন কোনো রেকর্ড সংযোজন করা হলে ইনডেক্স ফাইলগুলো আপনা-আপনি আপডেটেড হয়ে যায়। সর্টিং এ নতুন রেকর্ড যুক্ত করা হলে নতুন করে আবার ফাইলটিকে সর্ট করতে হয়।
- ইনডেক্সিং এ সটিং এর চেয়ে সময় তুলনামূলকভাবে কম লাগে।
- ইনডেক্সিং-এর মাধ্যমে সর্ট করা নতুন ইনডেক্স ফাইল তৈরি হয় এবং মূল টেবিল ফাইল অপরিবর্তিত থাকে। এতে স্মৃতিতে অতিরিক্ত জায়গা প্রয়োজন। সর্টিং-এর মাধ্যমে সর্ট করা হলে মূল টেবিল ফাইল সর্টেড (পরিবর্তিত) হয় বলে অতিরিক্ত জায়গার প্রয়োজন নেই।
ডেটাবেজ রিলেশন
ডেটাবেজের অন্তর্গত একাধিক ডেটা ফাইল থেকে ডেটা নিয়ে কাজ করার প্রয়োজনে ডেটা ফাইলসমূহের মধ্যে সংযোগ স্থাপন করে নিতে হয়। বিভিন্ন ডেটা ফাইল থেকে ডেটা নিয়ে কাজ করার জন্য এরূপ সংযোগ স্থাপন করানোকে ডেটাবেজ রিলেশন বলা হয়। ডেটাবেজ রিলেশন বলতে আসলে ডেটাবেজের টেবিলগুলোর মধ্যে সর্ম্পক বোঝানো হয়। দুটো ডেটা টেবিলের মধ্যে রিলেশন করার জন্য অবশ্যই একটি কমন ফিল্ড থাকতে হবে। এ কমন ফিল্ডের উপর ভিত্তি করেই রিলেশন প্রতিষ্ঠিত হবে। রিলেশনাল ডেটাবেজ প্রোগ্রামে কতগুলো পরস্পর সম্পর্কিত অবজেক্টের সমন্বয়ে ডেটাবেজ গঠিত হয়। যে সকল অবজেক্টের সমন্বয়ে ডেটাবেজ গঠিত তা হচ্ছে টেবিল, কুয়েরি, ফর্ম, রিপোর্ট, ম্যাক্রো এবং মডিউল।
রিলেশনের প্রকারভেদ : একাধিক ডেটা ফাইলের মধ্যে উপাত্ত প্রক্রিয়াকরণের প্রয়োজনে প্রাইমারি কী ফিল্ডের ভিত্তিতে রিলেশন। স্থাপন করা যায়। ডেটাবেজের অন্তর্গত ডেটা ফাইলের মধ্যকার রিলেশনকে চার ভাগে ভাগ করা যায়।
১। One to One রিলেশন: যদি কোন ডেটাবেজের কোনো টেবিলের একটি রেকর্ডের সাথে অন্য টেবিলের একটি মাত্র রেকর্ডের মধ্যকার রিলেশনকে One to One রিলেশন বলা হয়। যেমন: স্কুলের ডেটাবেজের Exam ফাইলের একটি রেকর্ড Personal ফাইলের কেবল একটি রেকর্ডের সঙ্গে সম্পর্কযুক্ত হতে পারে।
২। One to Many রিলেশন: কোন ডেটাবেজের কোনো একটি টেবিলের একটি রেকর্ডের সাথে অন্য টেবিলের একাধিক রেকর্ডের রিলেশনকে One to Many রিলেশন বলে। যেমন- Business Center নামক ডেটাবেজের বিক্রেতাদের তথ্যের জন্য Sales ফাইলের একটি রেকর্ড, ক্রেতাদের তথ্যের জন্য ব্যবহৃত Customer ফাইলের একাধিক রেকর্ডের সঙ্গে সম্পর্কিত হতে পারে। কারণ একজন বিক্রেতা একাধিক ক্রেতার কাছে পণ্য বিক্রি করে থাকে।
৩। Many to One রিলেশন : এই রিলেশন হচ্ছে One to Many রিলেশনের বিপরীত। যদি কোন একটি টেবিলের একাধিক রেকর্ড অপর এক বা একাধিক টেবিলের একটি রেকর্ডের সাথে সম্পর্কিত হয় তখন তাদের মধ্যকার রিলেশনকে Many to One রিলেশন বলা হয়। যেমন- একটি ডেটাবেজের শিক্ষার্থীদের টেবিলের একাধিক রেকর্ড পিতার টেবিলের একটি রেকর্ডের সঙ্গে সম্পর্কিত হতে পারে। ফলে শিক্ষার্থী এবং পিতার টেবিলের মধ্যে প্রয়োজনে Many to One রিলেশন তৈরি করা যায়।
৪। Many to Many রিলেশন: যদি কোন ডেটাবেজের অন্তর্গত দুটি টেবিল এমনভাবে সম্পর্কযুক্ত হয় যে, প্রথম টেবিলের একটি রেকর্ড দ্বিতীয় টেবিলের একাধিক রেকর্ডের সঙ্গে সম্পর্কযুক্ত, আবার দ্বিতীয় টেবিলের একটি রেকর্ড প্রথম টেবিলের একাধিক রেকর্ডের সঙ্গে সম্পর্কযুক্ত হয়, তখন তাদের মধ্যকার সম্পর্ককে বলা হয় Many to Many রিলেশন। Many to Many রিলেশন তৈরি করতে হলে তৃতীয় একটি টেবিল তৈরি করতে হয়। এই তু তীয় টেবিলটিকে জাংশন টেবিল বলা যায়। জাংশন টেবিলে উভয় টেবিলের প্রাইমারী কী ফিল্ড থাকে। জাংশন টেবিলটি One to Many এবং Many to One এর মত কাজ করে।
রিপোর্ট
রিপোর্ট শব্দের আভিধানিক অর্থ হলো প্রতিবেদন। ডাটাবেজ থেকে প্রয়োজনীয় ডাটাসমূহ প্রতিবেদন আকারে প্রর্দশনের ব্যবস্থাকে রিপোর্ট বলে। সাধারণত কোন তথ্য সরবরাহ বা বিতরণ করার জন্য রিপোর্ট ব্যবহৃত হয়। ডাটা টেবিল থেকে প্রয়োজনীয় তথ্যাবলি কলাম ও রো বা রেকর্ড অনুযায়ী সাজিয়ে রিপোর্ট উপস্থাপন করা হয়। সামারি রিপোর্টের মাধ্যমে সংক্ষিপ্ত ডেটা গ্রুপ আকারে উপস্থাপন করা যায়। রির্পোটকে সুন্দরভাবে উপস্থাপনের জন্য যখন পেজ মার্জিন, হেডার, ফুটার ইত্যাদি নির্ধারণ করা হয়, তখন তাকে ফরমেটেড রির্পোট বলা হয়। এ রির্পোটের বিভিন্ন অংশ আছে। যেমন-Report Header, Page Header, Group Header, Detail, Page Footer, Report Footer.
ডেটা সিকিউরিটি
অননুমোদিত ব্যক্তির (unauthorized) হাত থেকে ডেটাকে মুক্ত রাখার পদ্ধতিকে বলা হয় ডেটা সিকিউরিটি।
ডেটা এনক্রিপ্টশন (Data Encryption): ডেটার নিরাপত্তা নিশ্চিত করার জন্য ডেটাকে উৎস হতে গন্তব্যে প্রেরণের পূর্বে যে বিশেষ পদ্ধতিতে পরিবর্তন করা হয় তাকে ডেটা এনক্রিপশন পদ্ধতি বলা হয়। ফলে প্রেরকের প্রেরিত ডেটা অন্য কোন অনির্দিষ্ট ব্যক্তি বা প্রতিষ্ঠান ব্যবহার করে সুবিধা পায় না। উৎস বা প্রেরক ডেটাকে এনক্রিপ্ট করে 'মাধ্যমের' ভেতর দিয়ে পাঠালে প্রাপক বা গন্তব্য ঐ এনক্রিপ্টেড ডেটা ব্যবহারের পূর্বে ডিক্রিপ্ট করে। আর এভাবে সাইফার টেক্সটকে প্লেইন টেক্সটে রুপান্তর করাকে বলা হয় ক্রিপ্টোঅ্যানালাইসিস (Cryptanalysis)। কম্পিউটারের যে শাখায় ডেটা এনক্রিপশন নিয়ে গবেষণা ও কাজ করা হয়, তাকে বলা হয় ক্রিপ্টোগ্রাফি (Cryptography)। ডেটা এনক্রিপ্ট করার জন্য বহুল ব্যবহৃত দুটি স্ট্যান্ডার্ড হলো সিজার কোড (Caesar Code) ও ডেটা এনক্রিপশন স্ট্যান্ডার্ড (Data Encryption Standard-DES)। ডেটা এনক্রিপশনের মূল অংশ চারটি। যথা-
- প্লেইন টেক্সট: মূল ডেটাকে বলা হয় প্লেইন টেক্সট।
- সাইফার টেক্সট: মূল মেসেজকে এনক্রিপট করার পর প্রাপ্ত টেক্সট এনক্রিপশনের ফলে টেক্সটা দূর্বোধ্য হয়ে যায়।
- এনক্রিপশন এলগরিদম: গাণিতিক ফর্মূলা যা মেসেজ এনক্রিপট করার সময় ব্যবহার করা হয়।
- কী : গোপন কোড যা এনক্রিপট না ডিক্রিপ্ট করার কাজে ব্যবহার করা হয়। সাইফার টেক্সটকে প্লেইন টেক্সটে ফিরিয়ে আনার একটি প্রক্রিয়া।
ব্লকচেইন (Block chain)
ব্লকচেইন (Block chain) এক ধরনের ডেটাবেজ। এতে অনেক ডেটা ব্লক থাকে, এই সমস্ত ডেটা ব্লকে ক্রিপ্টোগ্রাফি প্রযুক্তি ব্যবহার করে ডেটা এনকোড করা হয় এবং এই ব্লকগুলি একে অপরের সাথে সংযুক্ত হয়ে একটি দীর্ঘ চেইন তৈরি করে। প্রতিটি ব্লকে রয়েছে তার ঠিক আগের ব্লকের একটি ক্রিপ্টোগ্রাফিক হ্যাশ (A hash pointer to the previous block) - অর্থাৎ প্রতিটি ব্লকের ডেটা তার পাশের ব্লকে সংরক্ষিত থাকে। এজন্য একবার ব্লকে ডেটা রেকর্ড হয়ে গেলে এই ডেটা আর মুছে ফেলা যায় না। ক্রিপ্টোকারেন্সি তথা বিট কয়েন- এর লেনদেনের মাধ্যমে ব্লকচেইন প্রযুক্তির ব্যবহার শুরু হয়।

মাইক্রোসফ্ট এ্যাক্সেস
MS-Access : মাইক্রোসফ্ট এ্যাক্সেস একটি ডেটাবেজ প্রোগ্রাম। এটি ব্যবহার করে ডেটাবেজ তৈরি করা, ফর্ম তৈরি করা, রির্পোর্ট তৈরি করা, শর্তানুযায়ী কুয়েরি করা এবং এ্যাপ্লিকেশন প্রোগ্রাম তৈরি করা যায়। মাইক্রোসফ্ট এ্যাক্সেসে ১০ - ৩০ ব্যবহারকারী এক সাথে update করতে পারেন। মাইক্রোসফ্ট এ্যাক্সেস Datasheet view তে কুয়েরি ফলাফল এবং টেবিল প্রদর্শন করে।